Evaluating Pre-Trained Models for User Feedback Analysis in Software Engineering
 Empirical Study on PTMs for App Review Classification
Empirical Study on PTMs for App Review Classification
Abstract
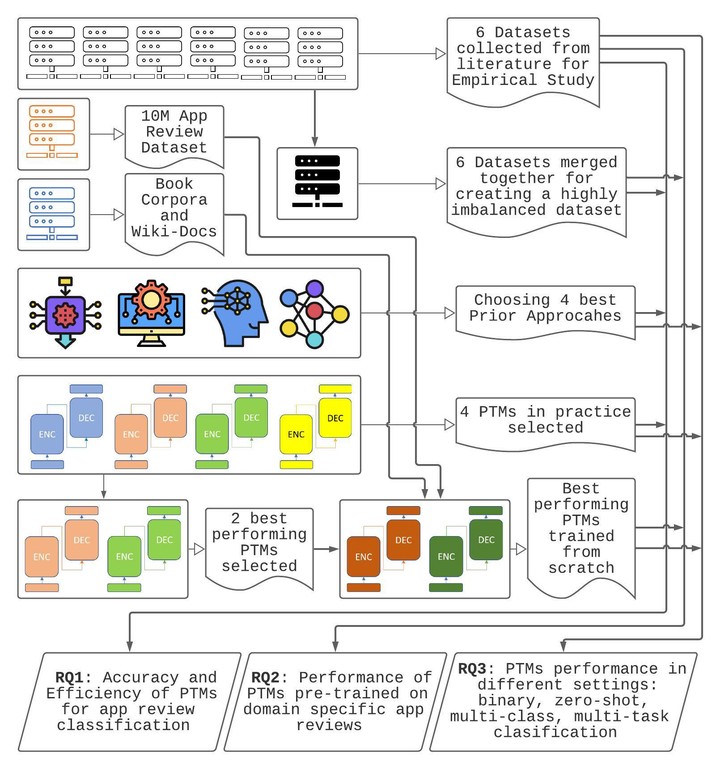
Reviews of mobile apps on app stores and on social media are valuable resources for app developers. Analyzing app reviews have proved to be useful for many areas of software engineering (e.g., requirement engineering, testing, etc.). Existing approaches rely on manual curating of a labeled dataset to classify app reviews automatically. In practice, new datasets must be labeled as the classification purpose changes (e.g., identifying bugs versus usability issues or sentiment), limiting the power of developed models to classify new classes or issues. Employing models that can produce the same or better result using less labeled data can eliminate the problem by reducing this manual effort. Recent Pre-trained Transformer based Models (PTM) are trained on large natural language corpora in an unsupervised manner to retain contextual knowledge about the language and have found success in solving similar Natural Language Processing (NLP) problems. However, the applicability of PTMs has not yet been explored for issue classification from app reviews. We explore the advantages of PTMs for app review classification tasks by comparing them with existing models; we also examine the transferability of PTMs by applying them in multiple settings. We carefully selected six datasets from the literature which contain manually labeled app review from Google Play Store, Apple App Store, and Twitter data. We empirically studied and reported the accuracy and time efficiency of PTMs compared to prior approaches using these six datasets. In addition, we investigated and evaluated the increased performance of the PTMs trained on app reviews (i.e., domain-specific PTMs). We set up different studies to evaluate PTMs in multiple settings - binary vs. multi-class classification, zero-shot classification (when new labels are introduced to the model), multi-task setting, and classification of reviews from different resources. In all cases, Micro and Macro Precision, Recall, and F1-scores is used and the time required for training and prediction with the models are also reported.
Mohammad Abdul Hadi
AI Security Researcher (Sr. Software Engineer)
AI Security Researcher at Huawei R&D — LLM architecture, malware analysis, and agentic multi-agent systems. 150+ citations across A* and A-rated conferences.
Fatemeh H Fard
Assistant Professor
I am interested in the applications of data science and machine learning for software engineering. Specifically I am working on the detection and prediction of defect/anomalous behaviour in software. This also requires using big data analysis in practice